Sculpting Language: GPT-2 Fine-Tuning with LoRa
Introduction
GPTs have burst onto the scene as the greatest thing that has ever happened to the NLP field. ChatGPT has sparked interest in many fields and disrupted the status quo like nothing else. In this article we will explore how applications like ChatGPT are created by taking a pre-trained GPT (Generative Pre-Trained Transformer) and fine-tuning the model for our task specific requirements.
What is GPT?
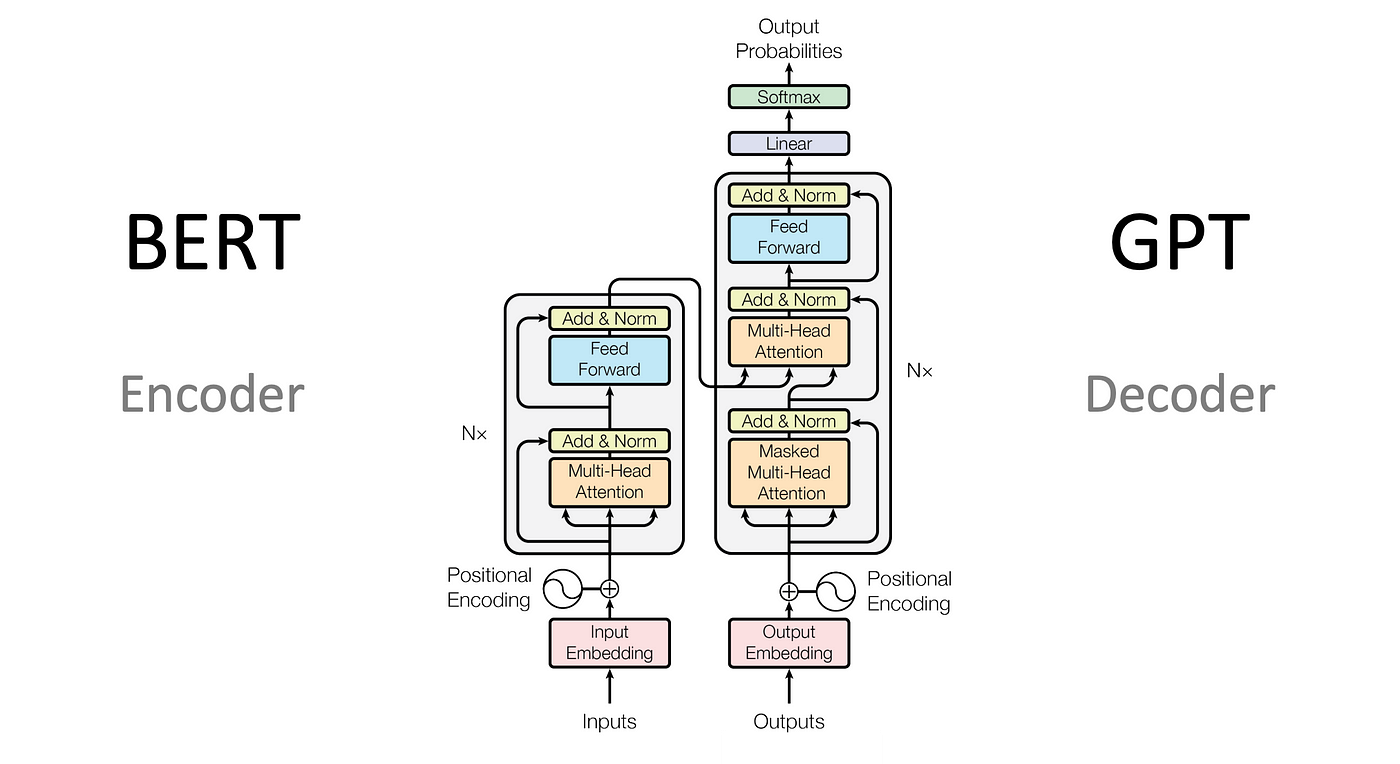
GPT is the decoder side from the original Transformers Paper, later research showed that the two pieces functioned fine individually creating two branches of transformer based research.
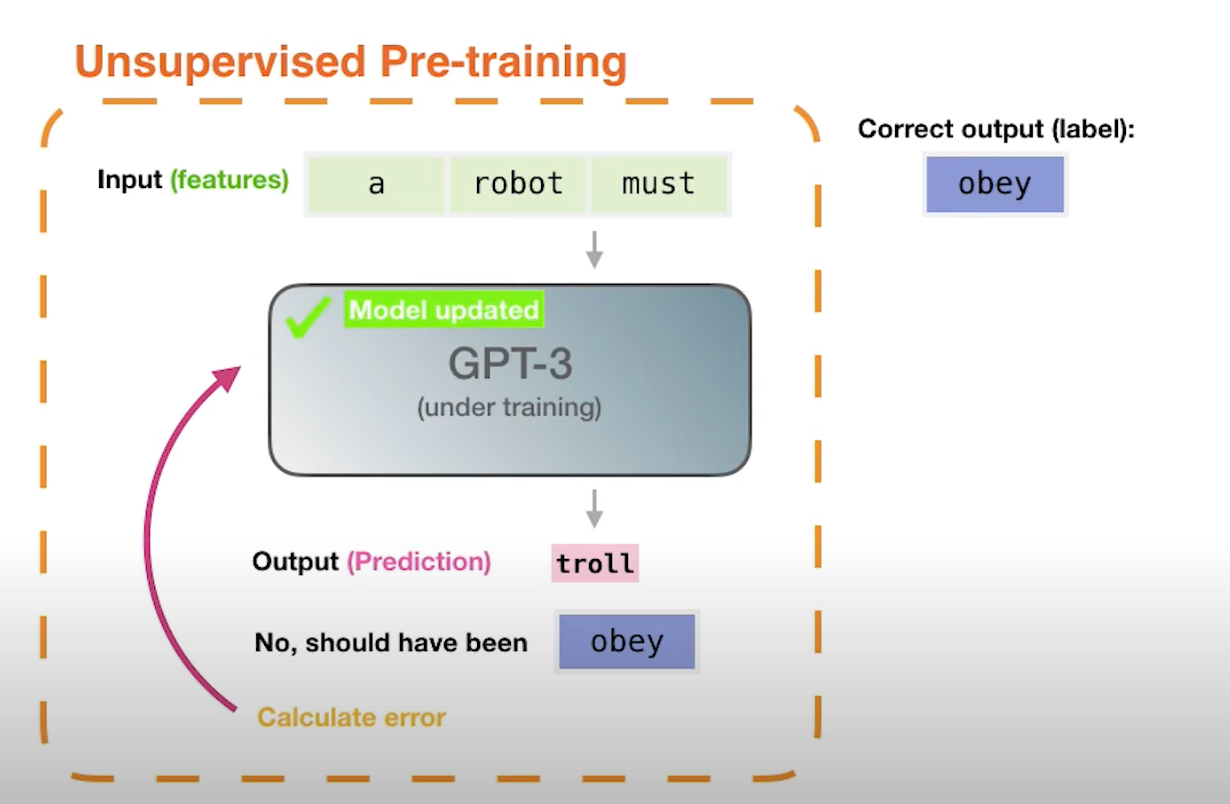
GPTs are trained to take in a sequence of words and predict the next word in the sequence. This allows them to train in a self-supervised manner since the ground truth for words 0 — N is just word N+1.
The revolutionary discovery in the transformer architecture is the idea of training self and cross attention modules, which allows the model to capture language’s bi-directional nature.
After training is complete, we are left with a model which is very good at predicting what word should logically come next in a sentence. But how do we get it to do Question-Answering like ChatGPT? This is where fine tuning takes place, we take a much smaller corpus and morph our question answer pairs task into a completion task so GPT can understand it.
For instance, if our QA was
Q: who was the first president
A: George Washington
We would feed the QA pair as a single paragraph
“Q: who was the first president
A: George Washington”
So at test time, when GPT sees “Q: who was the first president A:” it will know to spit out George Washington. It can then use this understanding of QA structure to answer never before seen questions in the fine-tuning by leveraging data it learned during pre-training.
What is LoRa?
When fine tuning, we want to adjust some model weights for our specific task. Changing the base weights — W — of the model can cause regressions in its ability to understand language, so usually those are frozen and a copy matrix W’ is created and is trained during fine-tuning. Then, the new model will use the base weights and the fine-tuned weights to make a prediction.
But wait, training that many weights would take an extremely long time! Maybe there is an easier way to train for our task specific use case, understanding our task should not be as complicated as understanding a whole language right? So why should we use as many weights as was used during language understanding?
This is where LoRa (Low Rank Adaptation) comes in, apparently the fine tuned W’ is very sparse, maybe we could represent it in a more light weight way?
Imagine W’ is a 1000x1000 matrix, perhaps we could represent W’ instead as a 1000x4 matrix * 4x1000 matrix, that gives us only 8,000 parameters to train instead of 1,000,000. That will be way faster, require way less memory and will hopefully be able to learn our task!

Our Mission
Let’s give it a go! our task will be to fine-tune GPT 2 (https://huggingface.co/openai-community/gpt2) on this quote tagging database https://huggingface.co/datasets/Abirate/english_quotes to allow our new model to preform a quote tagging task for us.
Let’s see how well the base GPT 2 does on this…
Input:
“Life is like a box of chocolates, you never know what you are gonna get” ->:Output:
aha that sounds good on paper.
If I could only be like, "Honey, let's go for a run now, you're going down the road with me, rightIt seems GPT 2 thinks I am asking it to complete some script for a play. Let’s fix that with fine-tuning!
Code
We are going to split our code into two stages, training and inference (testing). I had to use an NVIDIA GTX 1080 Ti with 11 GB of VRAM during training, for those of you without a GPU, I have put the weights up here. If you download those weights, you should be fine to do the inference piece without a GPU (it works fine on my macbook pro 2019).
Training
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = AutoModelForCausalLM.from_pretrained(
"gpt2",
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
# FREEZE WEIGHTS
for param in model.parameters():
param.requires_grad = False
# LoRa
config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
# LOAD AND STURCTURE DATA
data = load_dataset("Abirate/english_quotes")
def merge_columns(entry):
entry["prediction"] = entry["quote"] + " ->: " + str(entry["tags"])
return entry
data['train'] = data['train'].map(merge_columns)
print(data['train']['prediction'][:5])
data = data.map(lambda samples: tokenizer(samples['prediction']), batched=True)
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
print_trainable_parameters(model)
# TRAINING
trainer = transformers.Trainer(
model=model,
train_dataset=data['train'],
args=transformers.TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=100,
max_steps=500,
learning_rate=2e-4,
logging_steps=1,
output_dir='outputs',
auto_find_batch_size=True
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False
trainer.train()
torch.save(model.state_dict(), 'lora.pt')To fine-tune our model, we will have four steps: Load the pre-trained GPT 2 model and tokenizer, Set up our LoRa config, Load and Transform our fine-tuning data, and Train.
To Load our GPT 2 model and tokenizer, we just use Hugging face’s AutoModelForCausalLM and AutoTokenizer modules, we set the padding token to be the end of sentence token and then we will freeze the weights so they are not updated during fine-tuning.
Next, we will create our LoRa config, the most important parameter is r which is the rank of our LoRa matrices. This is what will replace the 1000x1000 W’ with the 1000 x r and r x 1000 matrices. The rest of the configurations are other hyper-parameters to play around with, which you can read about here. We use the config to wrap our base model with our LoRa weights for fine-tuning.
Next, we will load in our quote dataset, we will transform our data set so it makes sense to our GPT 2 model. We transform the two columns quote and tags into a single column prediction which is “{quote} ->: {tags}”. The “ ->:” is our special symbol to teach GPT 2 that after it sees this symbol, the quote is done and it should start spitting out tags.
Finally, we will train for 100 warm up steps and 500 total steps, with batch size 4x4 = 16. We save the output weights to lora.pt for later use.
Inference
import torch
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = AutoModelForCausalLM.from_pretrained(
"gpt2",
device_map='auto',
)
config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
model = model.to(device)
model.load_state_dict(torch.load("lora.pt", map_location=device))
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
with torch.no_grad():
batch = tokenizer("“Life is like a box of chocolates, you never know what you are gonna get” ->: ", return_tensors='pt').to(device)
output_tokens = model.generate(**batch, max_new_tokens=25)
print('\n\n', tokenizer.decode(output_tokens[0], skip_special_tokens=True))In our inference code, we load up the pre-trained GPT 2 and the LoRa Config in the same manner we did during training so that we can load in our saved model weights.
Now we will see what our fine tuned GPT 2 quote tagger outputs when given
"Life is like a box of chocolates, you never know what you are gonna get" ->:output:
vernacular', 'life', 'life-inspirational', 'life-inspirational-inspirational', 'Conclusion
Ta-Da! we have fine-tuned GPT2 to preform our specific task, this was done with a pretty low-powered GPU and a small set of data. If we fed this model more data and trained it for longer we may be able to achieve even better results!
It is true that ChatGPT 3 and ChatGPT 4 can probably achieve this quote tagging with few or zero shot learning. However, those models are much much larger than our lowly GPT 2 and could never run properly on a CPU device (even some GPU devices may struggle).
For comparison, GPT 4 has 1 trillion parameters, GPT 3 has 175 billion parameters and GPT 2 has 1.5 billion parameters (which is already pushing the limits of CPU inference).
For a lightweight, local, task specific LLM, you are probably better off fine tuning a small language model as we have done rather than using an overpowered behemoth like the ChatGPT models.

