You’re How Far Away? An exploration of different distance formulas

Today, we will explore some distance calculation formulas and when and where they are useful. Distance calculation is extremely useful in all sorts of applications, wether your are building a recommender system (checking distances between two users preferences), training ML model (calculating distances between your prediction and the ground truth) or actually calculating the distance between two users in your online dating app. The goal of this article is to serve as a handbook of all the different distance formulas so you can identify them in the wild and use them yourself.

The Formulas
The Euclidean

The most direct and well known formula, the euclidean distance is the length of a direct line between two points, it is commonly used for calculating losses for computing distances in a grid setting like for pixels on a screen.
# Euclidean
a = [2, 2]
b = [0, 0]
euclidean_dist = math.sqrt(math.fsum([math.pow(a[i] - b[i], 2) for i in range(2)]))
print(euclidean_dist)The Cosine

The Cosine difference is intuitively just 1 minus the cosine similarity. The Cosine similarity is used to measure the similarity between the direction of two points (w.r.t the origin). Because the cosine similarity does not care about magnitude, it is a great use when the magnitude is not relevent. For example, when comparing the sentiment difference between two sentences, we do not care about the respective lengths, so the cosine difference would work well in this case.
# Cosine
a = [1, 4]
b = [1, 0]
a_dot_b = math.fsum([a[i] * b[i] for i in range(2)])
a_mag = math.sqrt(math.fsum([a[i] * a[i] for i in range(2)]))
b_mag = math.sqrt(math.fsum([b[i] * b[i] for i in range(2)]))
cosine_sim = a_dot_b / (a_mag * b_mag)
print( 1 - cosine_sim)The Hamming
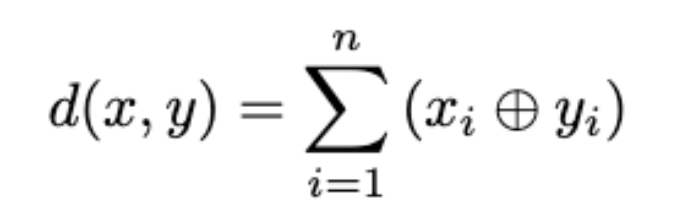
The Hamming distance is usually used on two binary strings. It is simply the sum of the bitwise XOR operations. The XOR operation is 1 if and only if the two values are different. It is used mostly for error checking of data sent over a network.
# hamming
a = [1, 3, 5, 7]
b = [1, 2, 5, 12]
dist = 0
for i in range(len(a)):
if a[i] != b[i]:
dist += 1
print(dist)The Manhattan
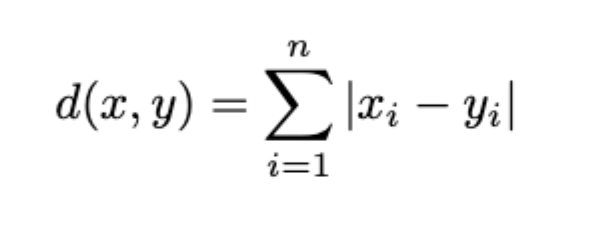
The Manhattan distance is used by doing an element wise distance for each element in a position vector, it is the distance as if you can only travel in the direction of one dimension at a time (like walking along the blocks of Manhattan, since we cannot walk through walls).
# Manhattan
a = [3, 2]
b = [5, -2]
manhattan_dist = math.fsum([math.fabs(a[i] - b[i]) for i in range(2)])
print(manhattan_dist)The Minkowski
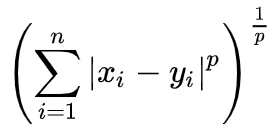
The Minkowski is the generalized version of the Manhattan (P = 1), Euclidian (P = 2) and Chebyshev (lim as P -> inf).
a = [4, -3, 0]
b = [7, 2, 5]
p = 3
dist = math.pow(math.fsum([ math.pow(math.fabs(a[i] - b[i]), p) for i in range(3)]), 1/p)
print(dist)The Chebyshev
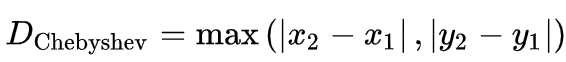
The Chebyshev distance is the max distance per element of a vector. “The Chebyshev distance is sometimes used in warehouse logistics, as it effectively measures the time an overhead crane takes to move an object (as the crane can move on the x and y axes at the same time but at the same speed along each axis” — Wikipedia
# chebyshev
a = [1, 2, 4, 8, 5]
b = [-1, 4, 9, 11, 6]
max_diff = math.fabs(a[0] - b[0])
for i in range(1, len(a)):
if math.fabs(a[i] - b[i]) > max_diff:
max_diff = math.fabs(a[i] - b[i])
print(max_diff)The Jaccard
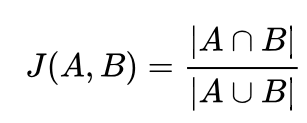
The Jaccard distance is usually used in categorical or binary data where each bit represents the presence of an item. We take the intersect of the two sets and divide by the union of the two, a Jaccard close to 1 means these are sets are very close, while a value close to 0 means the sets are very different. It is often used in similarity searches (like finding similar documents or movies to a given one).
# jaccard
a = [1, 2, 4, 8, 6]
b = [1, 4, 9, 11, 6]
union = []
union.extend(a)
for i in range(len(b)):
if b[i] not in a:
union.append(b[i])
intersect = []
for i in range(len(a)):
if b[i] in a:
intersect.append(b[i])
print(len(intersect) / len(union))The Haversine
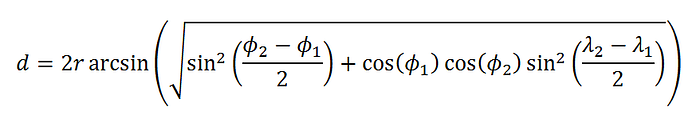
The Haversine distance is used to measure the distance between two lat, lng points on earth. R is the radius of the earth in meters. Phi 1 and 2 are the latitudes of our coordinates as radians and the lambdas are the longitudes as radians. This formula is pretty much only used to get distances between lat, lng coordinates.
# haversine
a = [72, 9]
b = [44, -63]
R = 6371000 # radius of Earth in meters
phi_1 = math.radians(a[0])
phi_2 = math.radians(b[0])
delta_phi = math.radians(b[0] - a[0])
delta_lambda = math.radians(b[1] - a[1])
a = math.sin(delta_phi / 2.0) ** 2 + math.cos(phi_1) * math.cos(phi_2) * math.sin(delta_lambda / 2.0) ** 2
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
print(R * c)The Dice
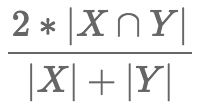
The Dice difference is very similar to the Jaccard in that it is used on categorical data, but the equation is different. We get the Dice by multiplying the intersect by 2 and dividing by the sum of the set sizes. Again, if the value is close to 0 it means the sets are very different, if it is close to 1 then they are very similar. The Dice and Jaccard are used in the same kinds of problems.
# dice
a = [1, 2, 4, 8, 6]
b = [1, 4, 9, 11, 6]
intersect = []
for i in range(len(a)):
if b[i] in a:
intersect.append(b[i])
print(2 * len(intersect) / (len(a) + len(b)))